Cracking the Amazon IT App Dev Engineer II Interview
You’ve clicked on this because you saw “Amazon IT App Dev Engineer II interview question” and your brain went:
“Yes please, I like money but I also like being prepared.”
Fair.
If you’re targeting an Amazon IT Application Developer Engineer II role, you’re in that awkward middle ground:
you’re not “junior” anymore, but they also expect you to design real systems, debug gnarly issues, and speak fluent
Leadership Principles in English.
This guide breaks down:
- What the role actually is (and is not)
- The types of interview questions you’ll face
- Sample questions with how to think about answers
- How to weave in Amazon’s Leadership Principles without sounding like a robot

What is an Amazon IT App Dev Engineer II, really?
Amazon’s job families are… unique.
An IT Application Development Engineer II typically sits in internal-facing tech teams: think tools for operations,
finance, HR, logistics, or internal services. You’re not usually building the public-facing retail site; you’re building
and maintaining internal applications that help the rest of Amazon do their jobs.
Common responsibilities (based on job descriptions Amazon posts):
- Design and implement features in internal tools and services
- Own and enhance existing applications (often Java, C#, Python, or similar)
- Integrate with AWS services (Lambda, S3, DynamoDB/RDS, SQS, etc.)
- Write and maintain APIs and backend services
- Troubleshoot production issues and handle on-call
with a side of “how do you work with messy real-world systems and customers?”
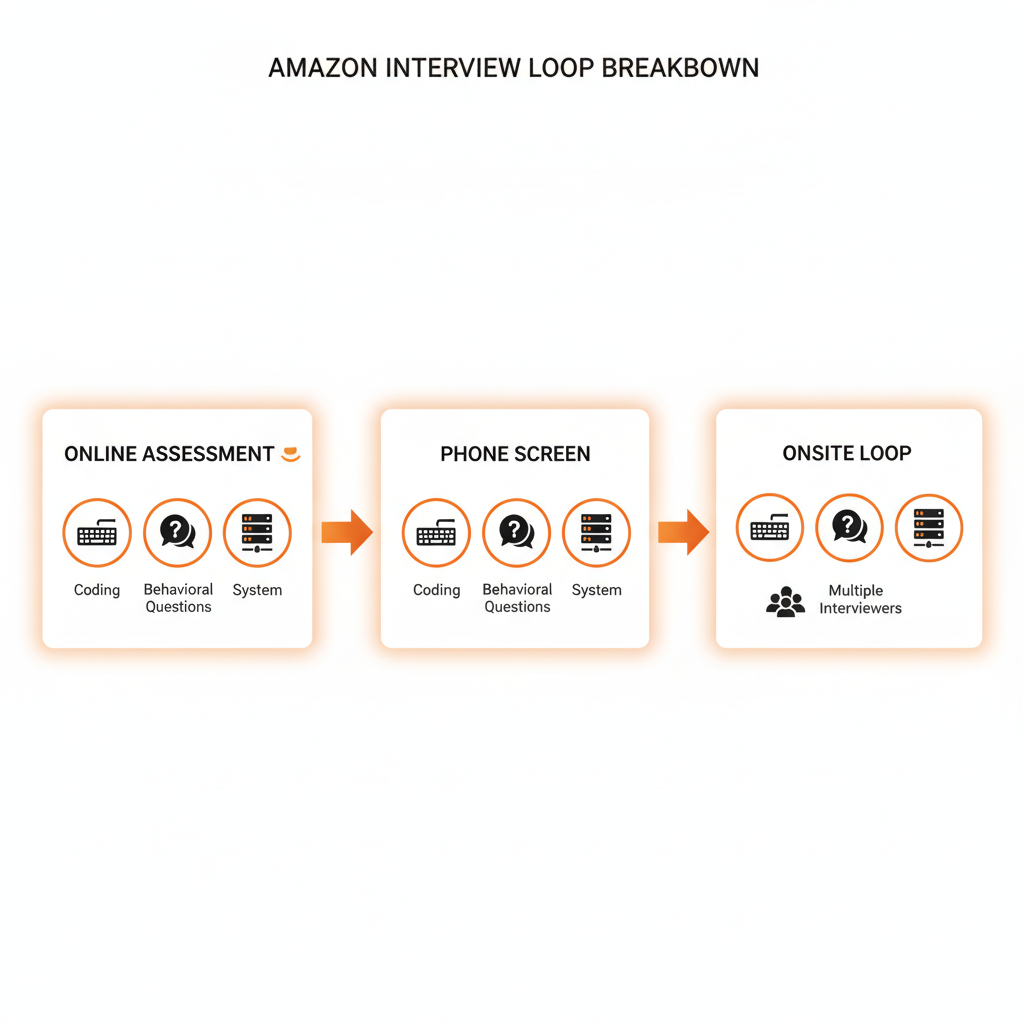
Interview format: What should you expect?
The exact loop can vary by team and location, but a fairly typical structure is:
-
Online assessment / technical screen
– Data structures & algorithms (medium LeetCode style)
– Basic coding and problem solving -
Phone / virtual interviews (1–2 rounds)
– Coding in a shared editor (arrays, strings, hash maps, basic trees)
– One or two behavioral questions -
Onsite or virtual loop (4–5 rounds)
Expect a mix of:
– Coding interviews
– System / application design (usually at the service/internal tools level, not internet-scale distributed systems, but still serious)
– Role-specific interviews (e.g., troubleshooting, integration, operations, internal customer scenarios)
– Behavioral / LP interviews (“Tell me about a time…”)
Every interviewer is also assessing Leadership Principles. They’re not optional background flavor; they are part of the scorecard.
Core categories of Amazon IT App Dev Engineer II interview questions
Let’s break the interview questions into buckets you can actually study for.
1. Coding & Problem-Solving Questions
You’ll get typical software dev style questions, usually in a mainstream language (Java, Python, C#, etc.).
These are often moderate difficulty, but you must code cleanly and think aloud.
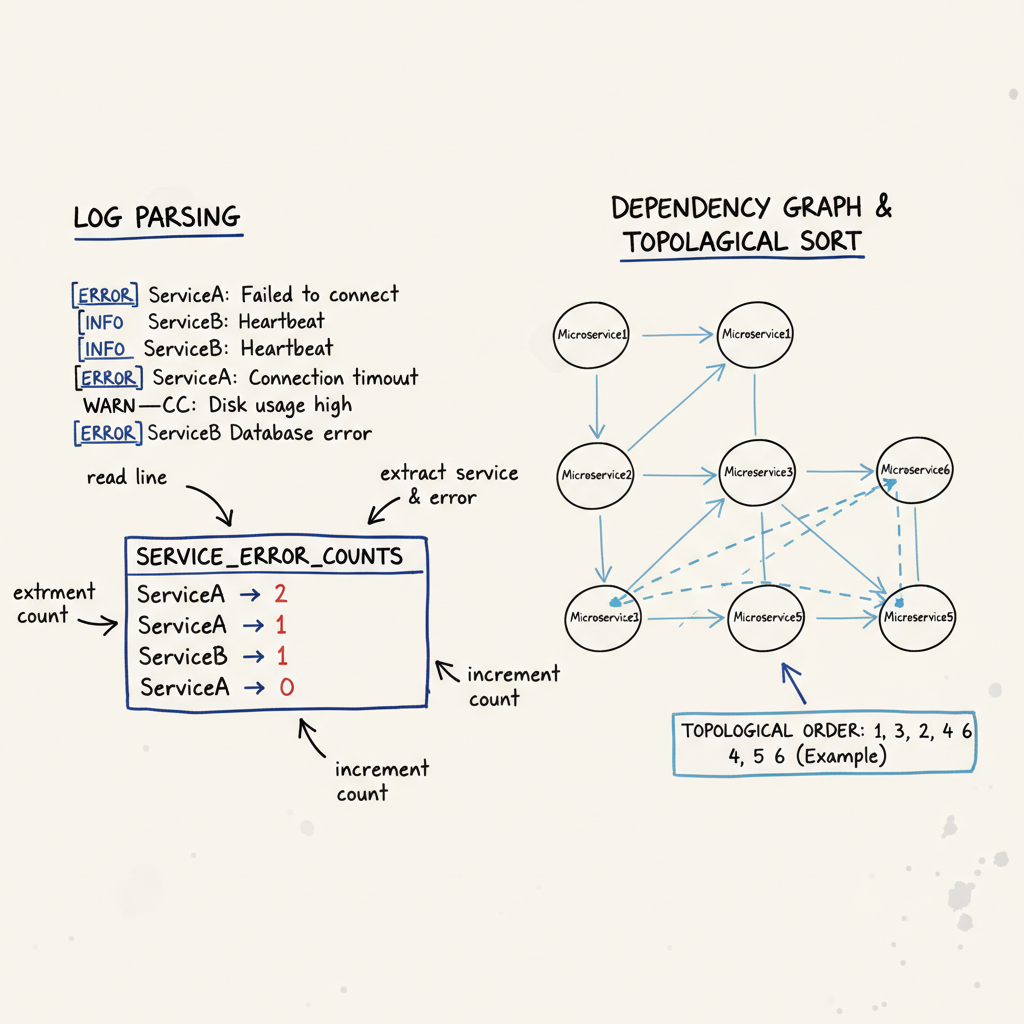
Example Coding Question 1: Log Aggregation & Error Counts
You’re given a stream (or list) of log entries from an internal application. Each entry is a string in the form:
"<timestamp> <level> <serviceName> <message>"
For example:
"2025-10-23T10:15:30Z ERROR PaymentsService Failed to charge card"Write a function that, given a list of such log lines and a log level (e.g., “ERROR”),
returns a mapping fromserviceNameto the count of logs at that level.
What they’re testing:
- String parsing and robustness
- Hash map usage
- Edge cases (malformed lines, missing fields)
How to approach it (high level):
- Split each line on whitespace.
- Validate it has at least 4 parts.
- Extract
level(index 1) andserviceName(index 2). - If
level == targetLevel, increment a counter for that service. - Return the dictionary/map.
Follow-ups they might ask:
-
How would you handle huge log files you can’t load into memory at once?
(Talk about streaming, iterators, batching, maybe using S3 + Athena or Kinesis in real life.) - How would you extend this to support multiple levels at once?
scalability, correctness, and maintainability.
Example Coding Question 2: Dependency Resolution (Topological Sort Lite)
You’re given a list of internal services and their dependencies. For example:
A -> [B, C]means A depends on B and C.
Given this mapping, produce an order in which services can be deployed so that dependencies
are deployed before dependent services. If no valid order exists (due to cycles), indicate that.
This is essentially topological sorting using DFS or Kahn’s algorithm.
What they’re testing:
- Graph representation (adjacency list)
- Detection of cycles
- Using DFS with visited + recursion stack or in-degree approach
How to talk through it:
- Represent services and deps as a graph.
- Use in-degree + queue (Kahn’s algorithm).
- If at the end the number of processed nodes < total nodes, there is a cycle.
Nice bonus: Connect this to real-world IT app dev: deployments across microservices, ordering of data migration jobs, etc.
2. System & Application Design Questions
At level II, you’re not expected to architect all of Amazon, but you are expected to design
small-to-medium internal systems.
Common patterns:
- CRUD applications for internal teams
- Workflow or approval systems
- Internal dashboards and reporting tools
- Integration with a few core AWS services
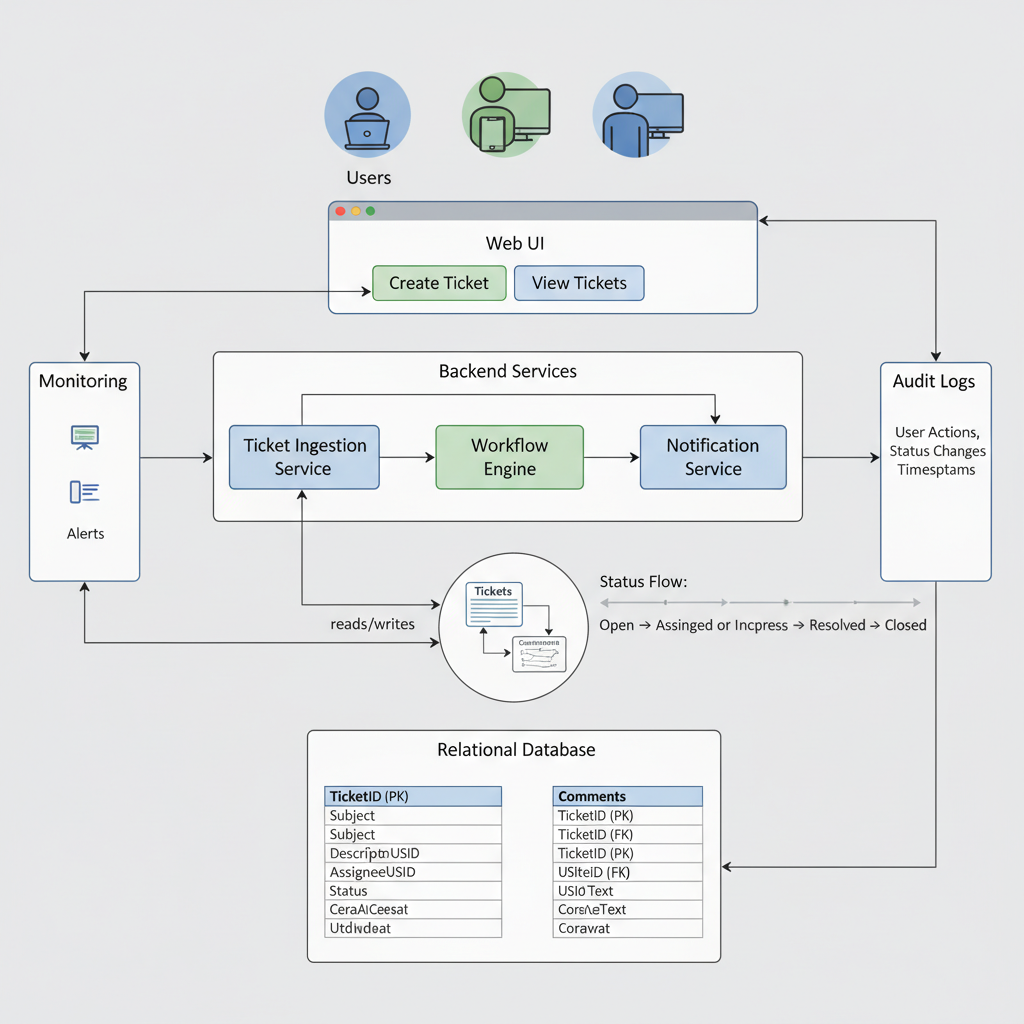
Example Design Question: Design an Internal Ticketing Tool for IT Requests
Your internal customers (Amazon employees) submit IT support tickets: hardware issues, software access, etc.
Design an application to handle:
– Ticket creation
– Assignment to IT engineers
– Status tracking (Open, In Progress, Resolved, Closed)
– Basic search/filtering by user, status, priority
How to structure your answer:
1. Clarify requirements
- Is this internal only? (Yes.)
- Scale? (Rough guesses: tens of thousands of employees, but not internet-scale.)
- Any SLAs or reporting requirements?
2. Outline high-level components
- Web/UI layer (internal web portal)
- Backend service / API (REST, maybe GraphQL)
- Data store (RDS for relational:
Tickets,Users,Comments) - Auth via Amazon’s internal identity system (you can say “SSO/identity provider”).
3. Data model sketch
-
Ticket(id, user_id, assignee_id, title, description, status, priority, created_at, updated_at) -
Comment(id, ticket_id, author_id, message, created_at)
4. Key flows
- Ticket creation → validation → insert into DB → trigger notification to IT queue.
- Assignment flow (auto vs manual).
- Status updates + event logging.
5. Non-functional requirements
- Reliability: handle retries and idempotency for ticket creation.
- Auditability: store history of status changes.
- Security: restrict who can see which tickets.
clear, extensible, and grounded in reality.
3. Troubleshooting & Operational Excellence Questions
Because IT App Dev Engineers often own production systems, you’ll be asked about
debugging and incident handling.
Example Troubleshooting Question
You deploy a new version of an internal service used by the Finance team. Soon after, they report that some
requests are timing out intermittently. The metrics show increased latency and error rates.
Walk me through how you would debug and resolve this.
How to structure your response:
-
Scope & impact
– Which endpoints are affected? All regions or specific ones?
– Are there recent config changes, dependency updates, or infra changes? -
Check metrics & logs
– Look at latency, CPU, memory, DB connections, error rates by endpoint.
– Identify patterns: specific request sizes? specific users? peak times? -
Narrow down hypotheses
– Example: DB connection pool exhaustion, N+1 queries, new network call added, slow external dependency. -
Reproduce in lower env if possible
– Run load tests or replay traffic. -
Mitigate quickly
– Roll back deployment if necessary.
– Add temporary throttling or circuit breaker if dependency is slow. -
Root cause & long-term fix
– Optimize queries, cache responses, or increase resources with justification.
– Add better telemetry so next time the signal is clearer.
Use phrases like “I’d start by…”, “I’d verify…”, “If that didn’t explain it, my next step would be…”
to show structured thinking.

4. Behavioral (Leadership Principles) Questions
For an Amazon interview, this part is non-negotiable. Expect deep dives on:
- Customer Obsession (internal customers count!)
- Ownership
- Dive Deep
- Deliver Results
- Learn and Be Curious
You’ll often get follow-ups like: “What EXACTLY did you do?” or “What did you learn and do differently afterward?”
Framework to use: STAR (Situation, Task, Action, Result)
Keep answers structured:
- Situation – Brief context.
- Task – What you had to achieve.
- Action – What YOU specifically did (not the team).
- Result – Numbers or concrete outcomes where possible.
Example Behavioral Question 1: Ownership
Tell me about a time you owned a project end-to-end.
Strong answer shape:
- Situation: An internal tool was unreliable, causing frequent incidents.
- Task: You owned stabilizing it and reducing incidents.
-
Action: You analyzed logs, identified top 3 recurring failures, implemented fixes, added health checks,
and improved alerting. - Result: Incidents dropped by 70%, and on-call pages reduced from X per week to Y.
Example Behavioral Question 2: Customer Obsession (Internal)
Tell me about a time you advocated for a customer need that wasn’t initially prioritized.
Good angles:
- You noticed internal users doing manual workarounds.
- You collected data (time lost, error rates) and shared it with PM/leadership.
- You proposed and built a feature or automation.
- Show measurable impact: hours saved per week, reduction in errors, etc.
You will reuse stories across questions.
Putting it together: How to prep effectively
Here’s a focused prep plan tailored to an Amazon IT Application Developer Engineer II interview.
1. Technical prep: Coding
-
Practice LeetCode Easy–Medium in topics like:
- Arrays, strings, hash maps, two pointers
- Basic trees/graphs
- Simple dynamic programming (optional, but useful)
- Time-box yourself to 30–40 minutes per problem.
- Practice speaking while coding: explain your thought process, trade-offs, and test cases.
2. Technical prep: Systems & App Design
-
Practice designing small systems:
- Internal ticketing system
- User management & role-based access
- Notification service (email + SMS)
-
For each design, explicitly cover:
- Requirements and constraints
- API surface
- Data model
- High-level architecture
- Non-functional requirements (scalability, reliability, security)
3. Role-specific prep: IT and Operations flavor
-
Think about times you:
- Ran or supported production systems
- Improved monitoring, logging, or alerting
- Investigated and resolved tricky incidents
- Automated manual tasks for internal teams
-
Be ready to talk about specific tools you’ve used (or analogs):
- Logging: CloudWatch, ELK, Splunk, etc.
- Monitoring: CloudWatch metrics, Prometheus, Datadog, etc.
- Deployment: CI/CD pipelines, canary deploys, rollbacks.
4. Behavioral prep: Leadership Principles in your language
- Pick 8–10 stories from your experience.
-
Map each story to 2–3 Leadership Principles (e.g., one story might cover
Ownership + Dive Deep + Deliver Results). -
Practice:
- Keeping stories under 3–4 minutes.
- Answering follow-ups like “What would you do differently?”
but due to lack of structured answers and LP alignment.
Sample answer snippets you can adapt
A quick taste of how to phrase answers.
For a coding question (after finishing code):
“I’ll walk through a quick test: for the input X, I expect Y. That validates that my parsing is correct and edge
cases like empty logs are handled. Complexity-wise, this is O(n) time and O(k) space where k is the number of services.
If we needed to support streaming logs from S3 or Kinesis, I’d refactor this to process iterators instead of
materializing everything in memory.”
For a behavioral question on an incident:
“We had an incident where our internal dashboard was timing out for the Ops team during peak hours. My role was to drive
the technical investigation. I started by checking latency graphs and saw a spike in DB query times. When I enabled slow
query logging, we discovered an unindexed filter on a large table. I proposed and implemented a new index, and then we
validated improvement in a test environment. After rollout, p95 latency dropped from 8 seconds to under 1 second, and we
documented the postmortem with guidelines on query reviews going forward.”
Steal the structure and adapt the details to your own experience.
Final checklist before your Amazon IT App Dev Engineer II interview
Run through this the day before your interview:
- I can solve Easy–Medium coding questions in 30–40 minutes while talking out loud.
- I’ve designed at least 3 small internal-style systems on a whiteboard or doc.
- I have 8–10 STAR stories mapped to Leadership Principles.
- I can describe 2–3 real incidents I’ve handled and how I debugged them.
- I can speak confidently about my experience with logging, monitoring, and deployments.
- I’ve read and internalized Amazon’s Leadership Principles and can explain what they mean in my own words.
If you can honestly check most of those boxes, you’re in a strong position.
And if the phrase “amazon it app dev engr ii interview question” brought you here at 1 a.m. the night before your loop…
close this tab in 20 minutes and go sleep. Your brain will thank you during the actual interview.
Leave a Reply